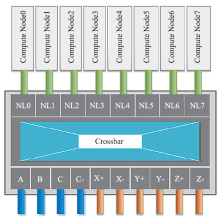
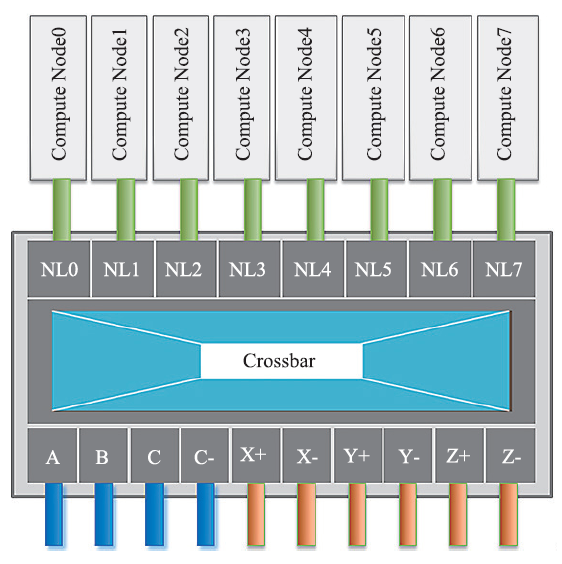
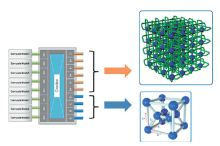
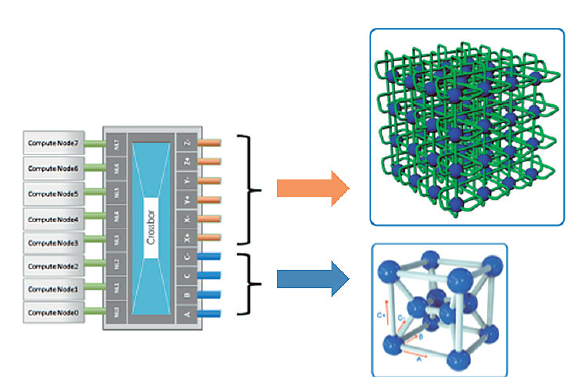
| [1] |
STROHMAIER E . TOP500 supercomputer[M]. 2006.
|
| [2] |
张云泉 . 2018年中国高性能计算机发展现状分析与展望[J]. 计算机科学, 2019,46(1):1-5.
|
| [3] |
JIAO L, WEIPING X, WUSHENG Z , et al. Equipment management and system maintenance on HPC platform[J]. Experimental Technology and Management, 2013,30(5):87-90.
|
| [4] |
KARJOTH G . Access control with IBM Tivoli access manager[J]. ACM Transactions on Information and System Security (TISSEC), 2003,6(2):232-57.
|
| [5] |
HERNANDEZ H M, WINTER R L . Sender device based pause system[M]. Google Patents. 2015.
|
| [6] |
GUANGBAO N, JIE M, BO L . GridView: A dynamic and visual grid monitoring system; proceedings of the High Performance Computing and Grid in Asia Pacific Region, 2004 Proceedings Seventh International Conference on, F, 2004 [C]. IEEE.
|
| [7] |
童端, 董小社, 李纪云 , et al. 基于OpenPBS的机群作业管理系统的设计与实现[J]. 计算机工程与应用, 2004,40(13):123-5.
|
| [8] |
赵宗弟, 胡凯, 胡建平 , et al. 基于PBS的集群作业调度策略的设计与实现[J]. 计算机与数字工程, 2006,34(11):123-7.
|
| [9] |
王翠萍 . LSF系统中作业调度的研究与优化[D]; 西安电子科技大学, 2009.
|
| [10] |
YOO A B, JETTE M A, GRONDONA M . SLURM: Simple Linux Utility for Resource Management[J]. 2003.
|
| [11] |
ABTS D, MARTY M R, WELLS P M , et al. Energy proportional datacenter networks[J]. Acm Sigarch Computer Architecture News, 2010,38(3):338-47.
|
| [12] |
面向E—HPC的新型高性能互连网络技术研究项目简介[J]. 计算机工程与科学, 2016, ( 11):2288.
|
| [13] |
FAANES G, BATAINEH A, ROWETH D , et al. Cray Cascade: A scalable HPC system based on a Dragonfly network[J]. 2012
|
| [14] |
AGARWAL A . Limits on interconnection network performance[J]. IEEE Transactions on Parallel and Distributed Systems, 1991,( 4):398-412.
|
| [15] |
BARKER K J, BENNER A F, HOARE R R, et al. On the Feasibility of Optical Circuit Switching for High Performance Computing Systems [C]. 2005.
|
| [16] |
VETTER J S, MUELLER F. Communication Characteristics of Large-Scale Scientific Applications for Contemporary Cluster Architectures; proceedings of the Vehicle Navigation & Information Systems Conference, F, 2002 [C].
|
| [17] |
BARROW-WILLIAMS N, FENSCH C, MOORE S W. A communication characterisation of Splash-2 and Parsec; proceedings of the IEEE International Symposium on Workload Characterization, F, 2009 [C].
|
| [18] |
SERVICE R F . China's planned exascale computer threatens Summit's position at the top[J]. 2018,359(6376):618.
|
| [19] |
赵玉国 . 基于OSGi技术的研究与应用[D]. 北京邮电大学, 2013.
|
| [20] |
李俊娥, 周洞汝 . “平台/插件”软件体系结构风格[J]. 小型微型计算机系统, 2007,( 5):110-5.
|
| [21] |
曾超宇, 李金香 . Redis在高速缓存系统中的应用[J]. 微型机与应用, 2013,32(12):11-3.
|
| [22] |
ZHOU Z, XU Y, LAN Z , et al. Improving Batch Scheduling on Blue Gene/Q by Relaxing 5D Torus Network Allocation Constraints; proceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium (IPDPS), F, 2015 [C].
|
| [23] |
ADACHI T, SHIDA N, MIURA K . The design of ultra scalable MPI collective communication on the K computer[J]. Computer Science - Research and Development, 28(2-3):147-55.
|
| [24] |
FAN Z, ZHENG C, YONG S , et al. HiNetSim: A Parallel Simulator for Large-Scale Hierarchical Direct Networks[J]. 2014.
|
 )
)