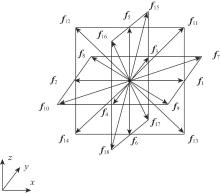
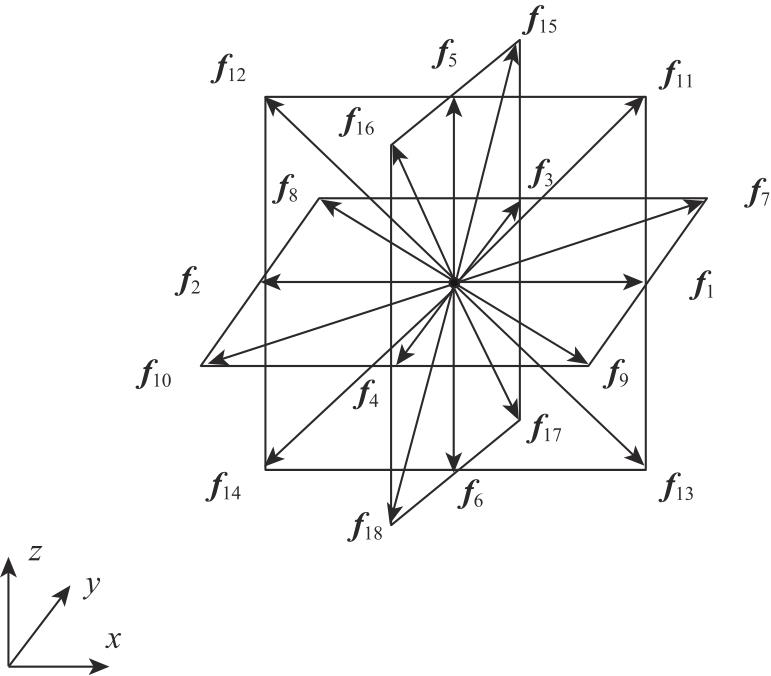
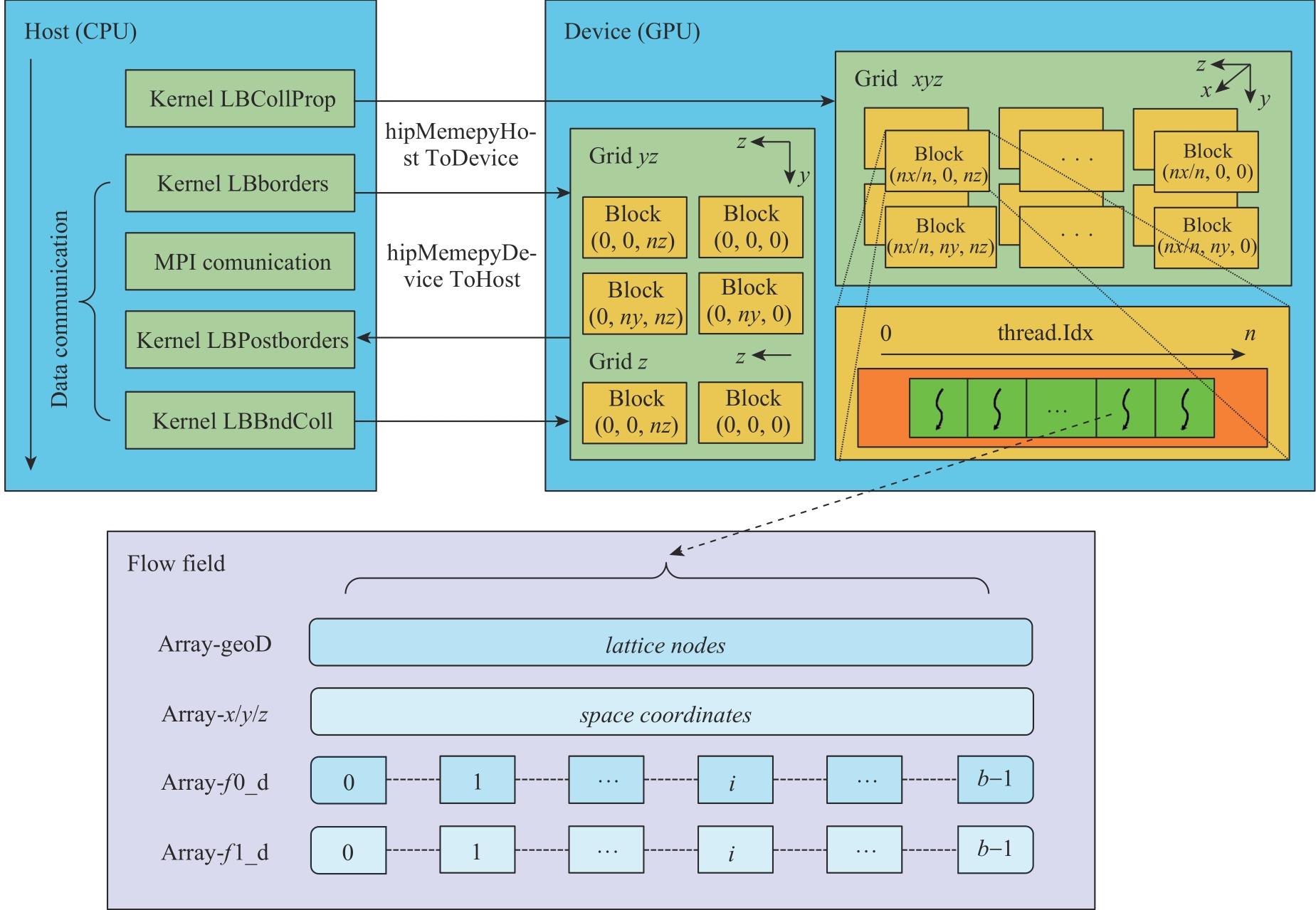
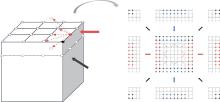
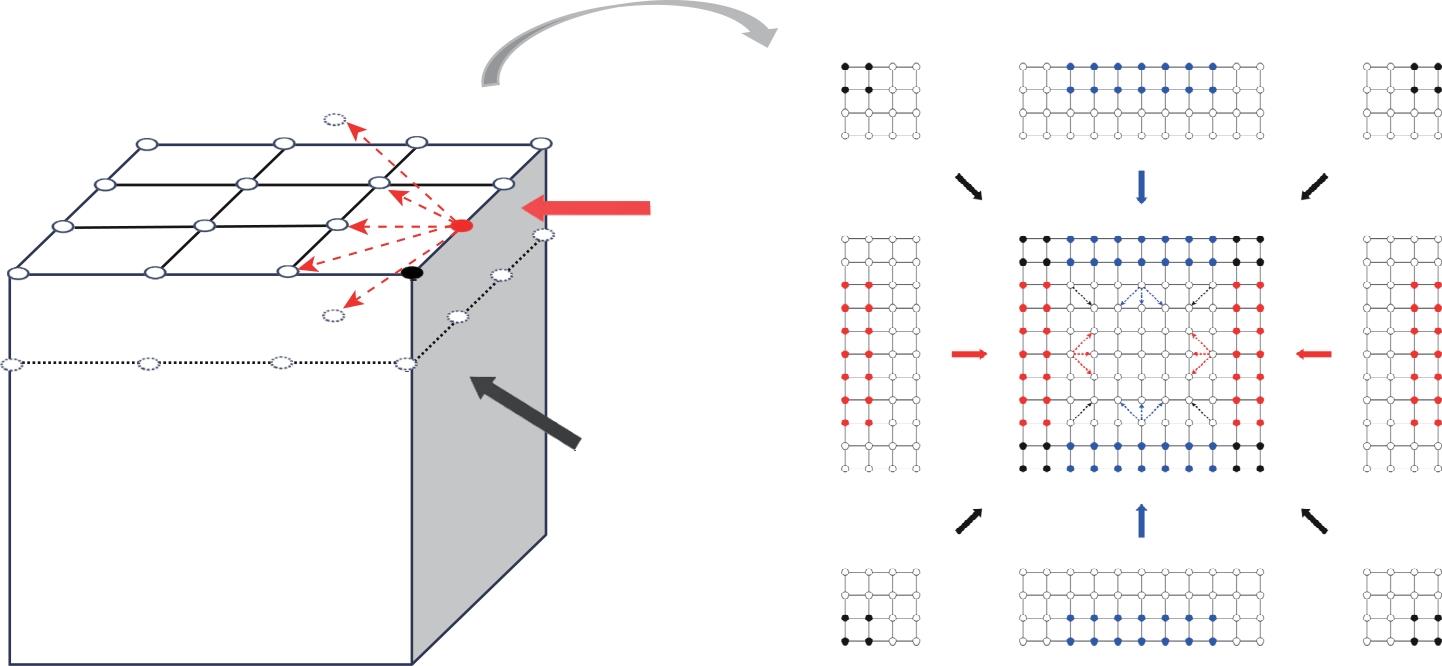
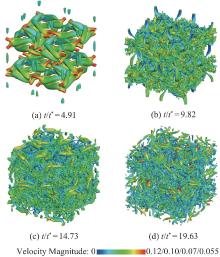
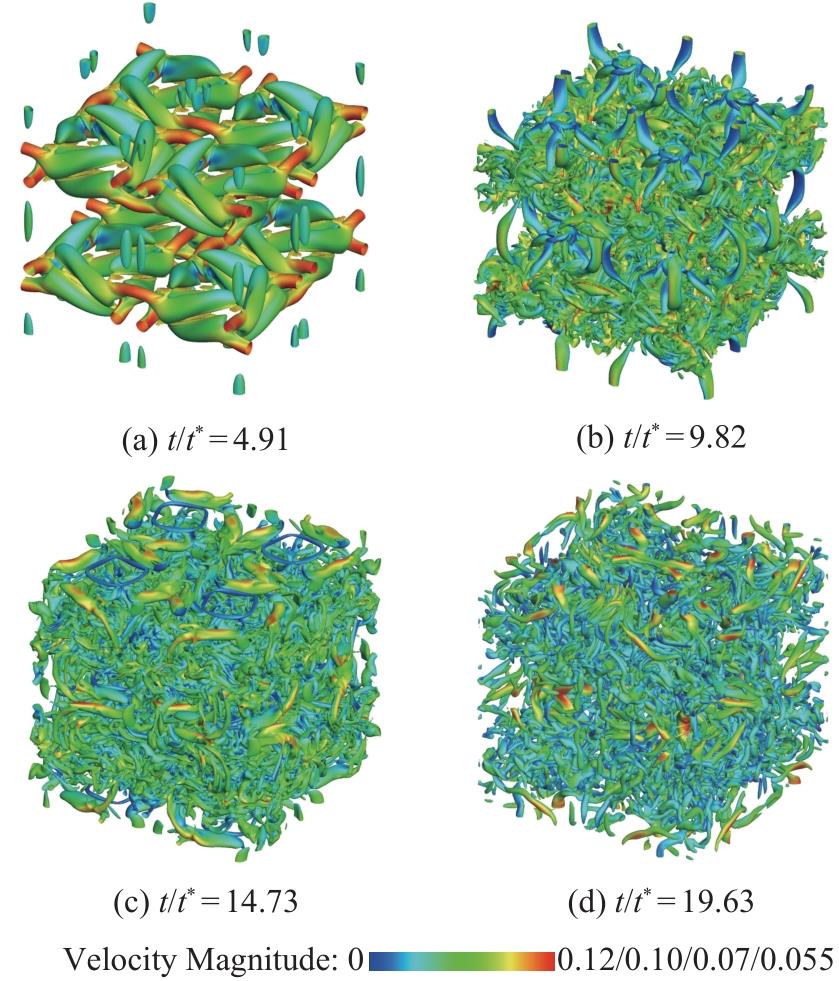
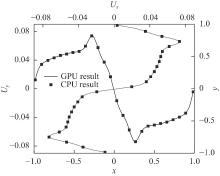
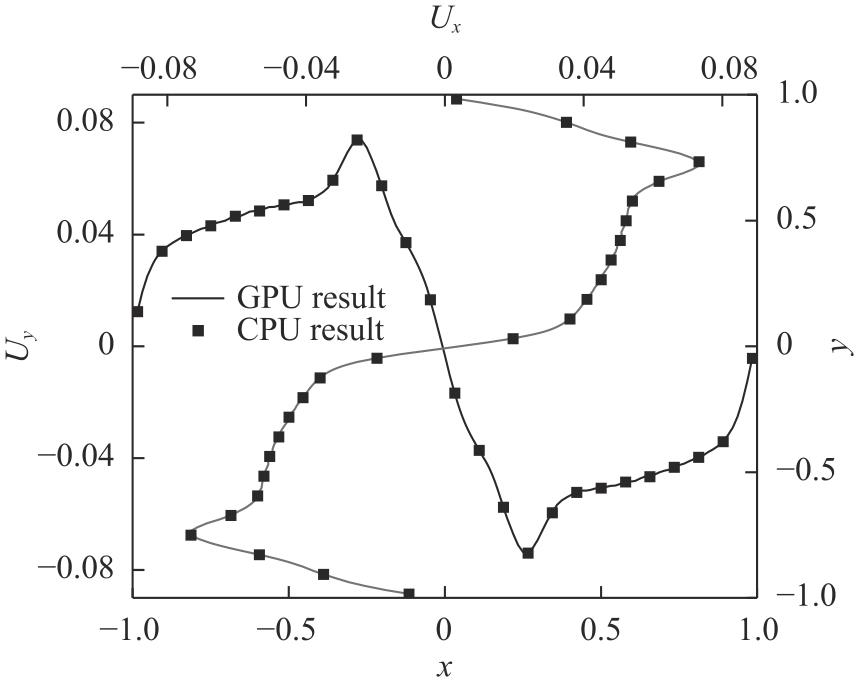
| [1] |
JÁSZ Á, RÁK Á, LADJÁNSZKI I, et al. Classical molecular dynamics on graphics processing unit architectures[J]. Wiley Interdisciplinary Reviews: Computational Molecular Science, 2020, 10(2): e1444.
|
| [2] |
NIEMEYER K E, SUNG C J. Recent progress and challenges in exploiting graphics processors in computational fluid dynamics[J]. The Journal of Supercomputing, 2014, 67: 528-564.
|
| [3] |
NAKAEGAWA T. High-performance computing in meteorology under a context of an era of graphical processing units[J]. Computers, 2022, 11(7): 114.
|
| [4] |
AMARASINGHE S, CAMPBELL D, CARLSON W, et al. Exascale software study: Software challenges in extreme scale systems[R]. DARPA IPTO, Air Force Research Labs, Tech. Rep, 2009: 1-153.
|
| [5] |
SLOTNICK J P, KHODADOUST A, ALONSO J, et al. CFD vision 2030 study: a path to revolutionary computational aerosciences[R]. 2014.
|
| [6] |
许爱国, 张广财, 李英骏, 等. 非平衡与多相复杂系统模拟研究——Lattice Boltzmann 动理学理论与应用[J]. 物理学进展, 2014, 34(3): 136-167.
|
| [7] |
LATT J, MALASPINAS O, KONTAXAKIS D, et al. Palabos: parallel lattice Boltzmann solver[J]. Computers & Mathematics with Applications, 2021, 81: 334-350.
|
| [8] |
张纲, 王利民, 葛蔚. 格子 Boltzmann 方法多 GPU 并行性能的研究[J]. 计算机与应用化学, 2017, 34(10):739-748.
|
| [9] |
XU A, SHI L, ZHAO T S. Accelerated lattice Boltz-mann simulation using GPU and OpenACC with data management[J]. International Journal of Heat and Mass Transfer, 2017, 109: 577-588.
|
| [10] |
XU A, LI B T. Multi-GPU thermal lattice Boltzmann simulations using OpenACC and MPI[J]. International Journal of Heat and Mass Transfer, 2023, 201: 123649.
|
| [11] |
XIAN W, TAKAYUKI A. Multi-GPU performance of incompressible flow computation by lattice Boltzma-nn method on GPU cluster[J]. Parallel Computing, 2011, 37(9): 521-535.
|
| [12] |
RIESINGER C, BAKHTIARI A, SCHREIBER M, et al. A holistic scalable implementation approach of the lattice Boltzmann method for CPU/GPU heterogeneous clusters[J]. Computation, 2017, 5(4): 48.
|
| [13] |
LIU Z, CHU X, LV X, et al. Sunwaylb: Enabling extreme-scale lattice Boltzmann method based computing fluid dynamics simulations on Sunway Taihulight[C]// 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), IEEE, 2019: 557-566
|
| [14] |
WOLFRAM S. Cellular automaton fluids 1: Basic theory[J]. Journal of Statistical Physics, 1986, 45: 471-526.
|
| [15] |
QIAN Y, DHUMIERES D, LALLEMAND P. Lattice BGK Models for Navier-Stokes Equation[J]. Europhysics Letters, 1992, 17(6): 479-484.
|
| [16] |
SHAN X, YUAN X F, CHEN H. Kinetic theory representation of hydrodynamics: a way beyond the Navier Stokes equation[J]. Journal of Fluid Mechanics, 2006, 550: 413-441.
|
| [17] |
XIANG X, SU W T, Hu T, et al. Multi-GPU lattice Boltzmann simulations of turbulent square duct flow at high Reynolds numbers[J]. Computers & Fluids, 2023, 266: 106061.
|
| [18] |
XIANG X, WANG L M. Lattice Boltzmann method for heat transfer in transitional flows with unified single-node curved boundary conditions[J]. International Journal of Heat and Mass Transfer, 2023, 210: 124167.
|
| [19] |
TÖLKE J. Implementation of a Lattice Boltzmann k-ernel using the Compute Unified Device Architecture developed by NVIDIA[J]. Computing and Visualization in Science, 2010, 13(1): 29.
|
| [20] |
LIU Z X, LI Y, SONG W. Regularized lattice Boltzm-ann method parallel model on heterogeneous platforms[J]. Concurrency and Computation: Practice and Experience, 2022, 34(22): e6875.
|
| [21] |
WANG X, TAKAYUKI A. Multi-GPU performance of incompressible flow computation by lattice Boltz-mann method on GPU cluster[J]. Parallel Computing, 2011, 37(9): 521-535.
|
| [22] |
MOHAMAD A A. Lattice boltzmann method[M]. Lo-ndon: Springer, 2011: 105-107.
|
| [23] |
HAUSSMANN M, SIMONIS S, NIRSCHL H, et al. Direct numerical simulation of decaying homogeneous isotropic turbulence—numerical experiments on stability, consistency and accuracy of distinct lattice Boltzmann methods[J]. International Journal of Modern Physics C, 2019, 30(09): 1950074.
|
| [24] |
GEIER M, LENZ S, SCHÖNHERR M, et al. Under-resolved and large eddy simulations of a decaying Taylor-green vortex with the cumulant lattice Boltz-mann method[J]. Theoretical and Computational Fluid Dynamics, 2021, 35: 169-208.
|
| [25] |
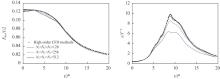
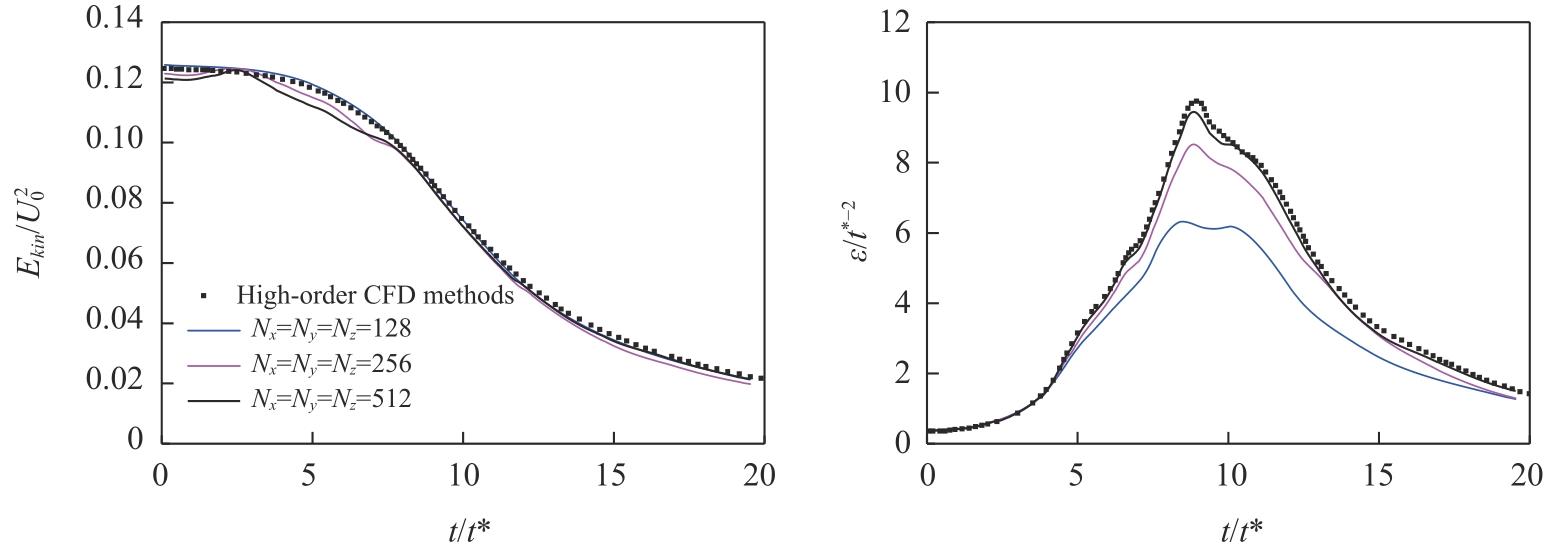
WANG Z J, FIDKOWSKI K, ABGRALL R, et al. Hi-gh-order CFD methods: current status and perspective[J]. International Journal for Numerical Methods in Fluids, 2013, 72(8): 811845.
|
| [26] |
LEHMANN M, KRAUSE M J, AMATI G, et al. Accuracy and performance of the lattice Boltzmann me-thod with 64-bit, 32-bit, and customized 16-bit number formats[J]. Physical Review E, 2022, 106(1): 015308.
|
| [27] |
李博, 李曦鹏, 张云, 等. 耦合Nvidia/AMD两类GPU的格子玻尔兹曼模拟[J]. 科学通报, 2009, 54(20):3177-3184.
|
| [28] |
DUAN X, GAO P, ZHANG M, et al. Neighbor-list-free molecular dynamics on sunway taihulight supercomputer[C]// Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2020: 413-414.
|
 ),孙培杰1,2,张华海1,王利民1,3,*(
),孙培杰1,2,张华海1,王利民1,3,*(