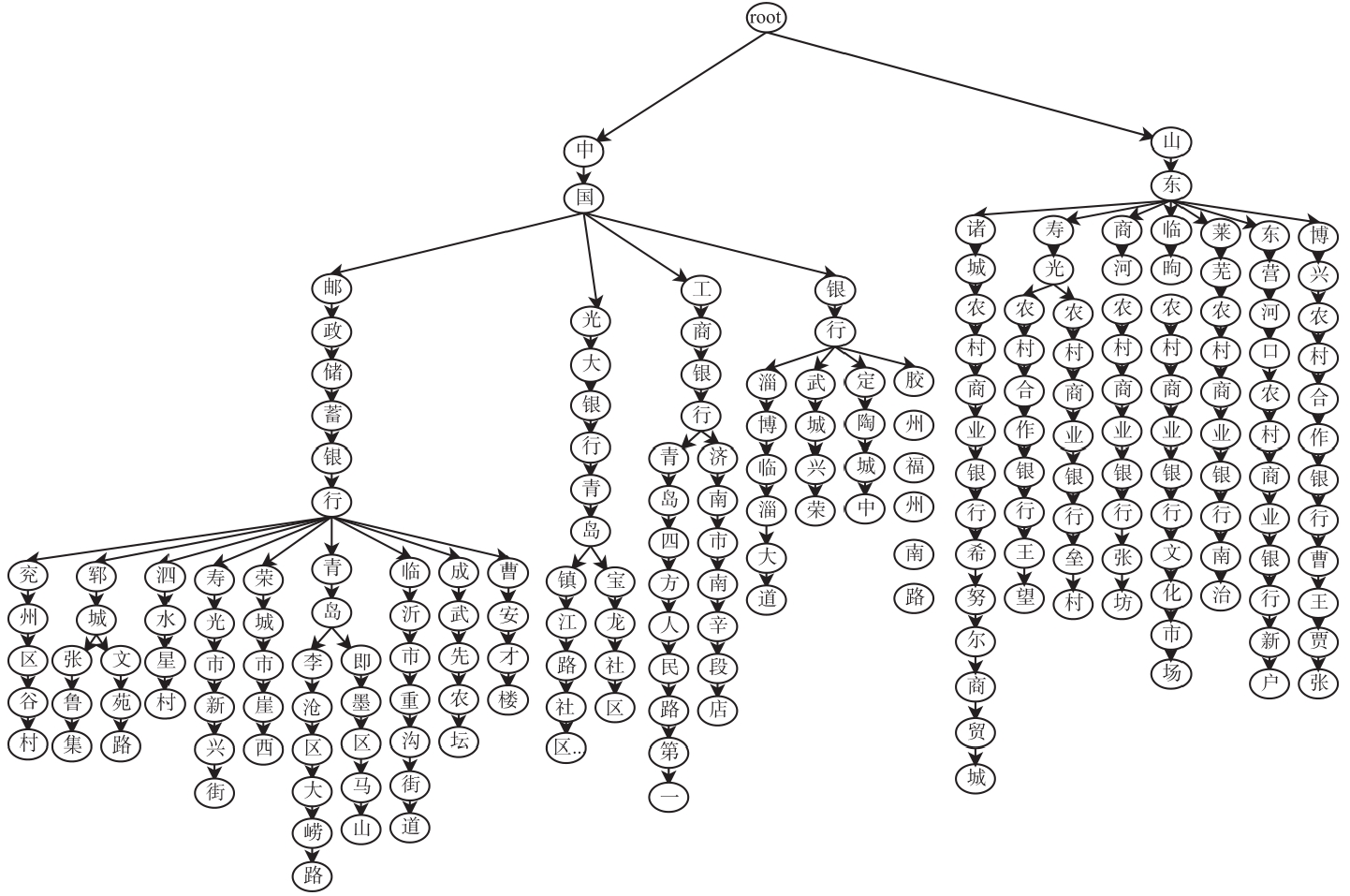
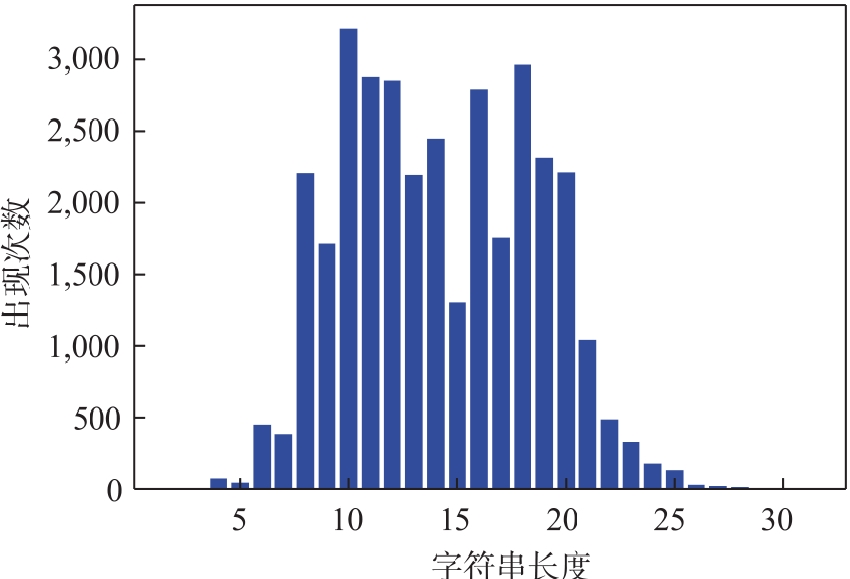
| [1] |
赵军. 科研实体识别及归一化的研究与系统实现[D]. 北京: 北京邮电大学, 2018.
|
| [2] |
胡潜, 吴茜, 董寒宇, 等. 基于作者和研究主题的科研机构名称演化关系识别研究[J]. 情报学报, 2023, 42(11): 1289-1299.
|
| [3] |
亓杰星, 彭金波, 傅洛伊, 等. 基于LEAM模型的机构命名实体归一化方法和系统[P]. 上海: CN2020 11141040. X, 2022-09-23.
|
| [4] |
BO Y, JUNWEI Y, SULAN Y. Research on rule-based normalization of institution name[J]. Data Analysis and Knowledge Discovery, 2015, 31(6): 57-63.
|
| [5] |
JIA Z, FANG Z, ZHANG H. Normalization of Web of Science Institution Names Based on Deep Learning[J]. Algorithms, 2024, 17(7): 312.
|
| [6] |
YIFEI C, XIAOYING L, AIHUA L, et al. A Deep Learning Model for the Normalization of Institution Names by Multisource Literature Feature Fusion: Algorithm Development Study.[J]. JMIR formative research, 2023, 7: e47434.
|
| [7] |
孙海霞, 李军莲, 吴英杰. 基于K-means的机构归一化研究[J]. 医学信息学杂志, 2013, 34(7): 41-44.
|
| [8] |
贾君枝, 曾建勋, 李捷佳, 等. 科研机构名称归一化实现[J]. 图书情报工作, 2018, 62(13): 103-110.
|
| [9] |
杨昭. 基于元路径的机构名称归一化研究[J]. 情报学报, 2020, 39(10): 1069-1080.
|
| [10] |
沈沛, 毛海涛, 胡文林, 等. 基于分段加权相似度匹配算法的中文科研机构名称归一化[J]. 信息技术与信息化, 2022(9): 59-62.
|
| [11] |
DONOHUE J C. Understanding Scientific Literatures: A Bibliometric Approach[J]. 1973.
|
| [12] |
KUMAR K M, SANKAR M D, MANISH G, et al. Trie-nlg: trie context augmentation to improve personalized query auto-completion for short and unseen prefixes[J]. Data Mining and Knowledge Discovery, 2023, 37(6): 2306-2329.
|
| [13] |
肖英, 赵林洁, 张宇, 等. 支持快速索引的高效大数据存储结构[J]. 计算机应用与软件, 2024, 41(3): 28-33.
|
| [14] |
张胜楠. 基于编辑距离的字符串相似度算法研究[J]. 现代计算机, 2023, 29(14): 23-26.
|
| [15] |
胡万亭, 杨燕, 尹红风, 等. 一种基于字频统计的组织机构名识别方法[J]. 计算机应用研究, 2013, 30(7): 2014-2016.
|
 ),姜树明2,*(
),姜树明2,*(