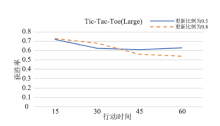
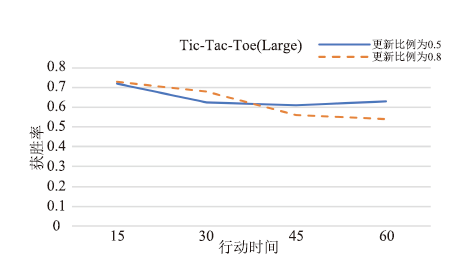
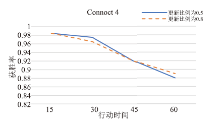
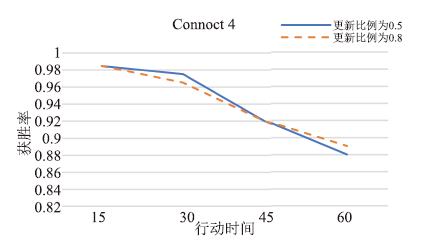
| [1] |
Hsu F H. Behind Deep Blue: Building the Computer that Defeated the World Chess Champion[M]. Princeton University Press, 2002: x.
|
| [2] |
Genesereth M, Love N, Pell B. General game playing: Overview of the AAAI competition[J]. AI magazine, 2005, 26(2): 62-62.
|
| [3] |
Thielscher M. General Game Playing in AI Research and Education[C]// the German Annual Conference on Artificial Intelligence (KI), Springer, Berlin, Heidelberg, 2011, 7006: 26-37.
|
| [4] |
Browne C B, Powley E, Whitehouse D, et al. A Survey of Monte Carlo Tree Search Methods[J]. IEEE Transactions on Computational Intelligence and AI in Games, 2012, 4(1): 1-43.
doi: 10.1109/TCIAIG.2012.2186810
|
| [5] |
Świechowski M, Park H, Mańdziuk J, et al. Recent Adva-nces in General Game Playing[J/OL]. The Scientific Wor-ld Journal, 2015:1-22. https://pubmed.ncbi.nlm.nih.gov/ 26380375/.
|
| [6] |
Świechowski M, Mańdziuk J. A Hybrid Approach to Parallelization of Monte Carlo Tree Search in General Game Playing[M]// Challenging Problems and Solutions in Intelligent Systems, Springer, Cham, 2016: 199-215.
|
| [7] |
张海峰, 刘当一, 李文新. 通用对弈游戏:一个探索机器游戏智能的领域[J]. 软件学报, 2016, 27(11): 2814-2827.
|
| [8] |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level Control through Deep Reinforcement Learning[J]. nature, 2015, 518(7540): 529-533.
doi: 10.1038/nature14236
|
| [9] |
Silver D, Huang A, Maddison C J, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search[J]. nature, 2016, 529(7587): 484-489.
doi: 10.1038/nature16961
|
| [10] |
Xiao C, Mei J, Müller M. Memory-Augmented Monte Carlo Tree Search[C]// the 32nd AAAI Conference on Artificial Intelligence, 2018: 1455-1461.
|
| [11] |
Pitrat J. A General Game Playing Program[M]// Findler N and Meltzer B: Artificial Intelligence and Heuristic Programming, Edinburgh University Press, 1971:125-155.
|
| [12] |
Pell B. Strategy Generation and Evaluation for Meta-Game Playing[D]// University of Cambridge, 1993.
|
| [13] |
Thielscher M. Systems with General Intelligence: A New Perspective (Invited Talk)[Z]// the 24th AAAI Confer-ence on Artificial Intelligence, 2010.
|
| [14] |
Clune J. Heuristic Evaluation Functions for General Game Playing[C]// the 22nd AAAI Conference on Artifi-cial Intelligence, 2007: 1134-1139.
|
| [15] |
Schiffel S, Thielscher M. Fluxplayer: A Successful Gen-eral Game Player[C]// the 22nd AAAI Conference on Artificial Intelligence, 2007: 1191-1196.
|
| [16] |
Finnsson H, Björnsson Y. Simulation-Based Approach to General Game Playing[C]// the 23rd AAAI Conference on Artificial Intelligence, 2008: 259-264.
|
| [17] |
Benacloch-Ayuso J L. RL-GGP[CP/OL]. http://users.dsic.upv.es/-flip/RLGGP/. 2012.
|
| [18] |
Finnsson H, Björnsson Y. Learning Simulation Control in General Game-Playing Agents[C]// the 24th AAAI Conference on Artificial Intelligence, 2010: 954-959.
|
| [19] |
Wang H, Emmerich M, Plaat A. Monte Carlo Q-learning for General Game Playing[J/OL]. arXiv preprint arXiv: 1802.05944, 2018.
|
| [20] |
Goldwaser A, Thielscher M. Deep Reinforcement Lea-rning for General Game Playing[C]// the 34th AAAI Conference on Artificial Intelligence, 2020, 34(02): 1701-1708.
|
| [21] |
Love N, Hinrichs T, Haley D, et al. General Game Pla-ying: Game Description Language Specification[R]. Stan-ford Logic Group Computer Science Department Stan-ford University. 2008.
|
| [22] |
Thielscher M. A General Game Description Language for Incomplete Information Games[C]// the 24th AAAI Conference on Artificial Intelligence, 2010: 994-999.
|
| [23] |
Thielscher M. GDL-III: A Description Language for Epistemic General Game Playing[C]// the 26th Internat-ional Joint Conference on Artificial Intelligence, 2017: 1276-1282.
|
| [24] |
Méhat J, Cazenave T. A Parallel General Game Player[J]. KI-künstliche Intelligenz, 2011, 25(1): 43-47.
doi: 10.1007/s13218-010-0083-6
|
| [25] |
Auer P, Cesa-Bianchi N, Fischer P. Finite-Time Analysis of the Multi-armed Bandit Problem[J]. Machine learning, 2002, 47(2): 235-256.
doi: 10.1023/A:1013689704352
|
| [26] |
Kocsis L, Szepesvári C. Bandit-Based Monte-Carlo Planning[C]// European conference on machine learning, Springer, Berlin, Heidelberg, 2006, 4212: 282-293.
|
| [27] |
Genesereth M, Björnsson Y. The International General Game Playing Competition[J]. AI Magazine, 2013, 34(2): 107-111.
doi: 10.1609/aimag.v34i2.2475
|
 ),JIANG Guifei1,*(
),JIANG Guifei1,*(