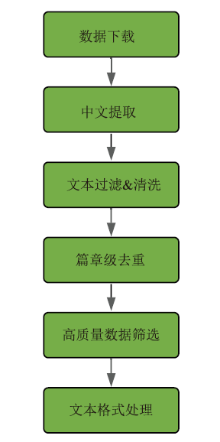
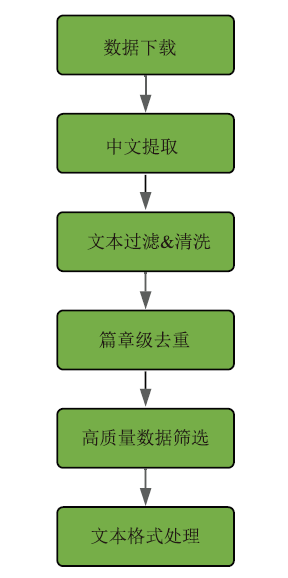
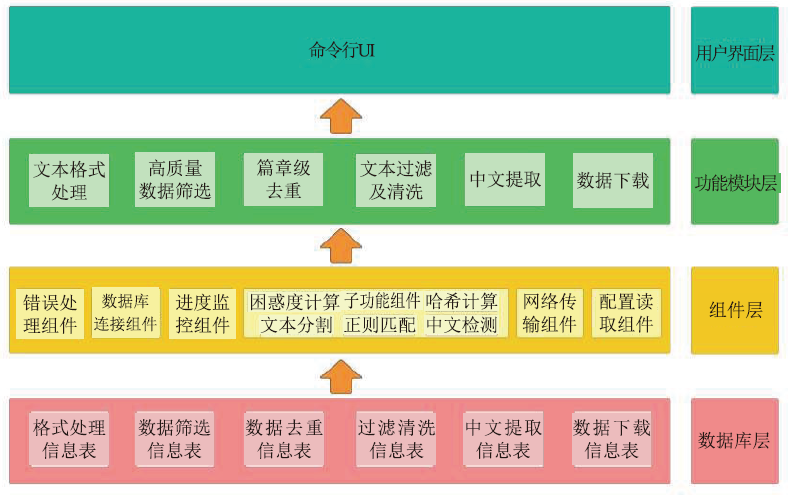
| [1] |
BROWN T B, MANN B, RYDER N, et al. Language Mo-dels areFew-Shot Learners[C/OL]. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, Neur-IPS 2020. https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
|
| [2] |
Yang Z, Dai Z, Yang Y, et al. XLNet: generalized autor-egressive pretraining for language understanding[C]// Proceedings of the 33rd International Conference on Ne-ural Information Processing Systems, 2019: 5753-5763.
|
| [3] |
Raffel C, Shazeer N, Roberts A, et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer[J]. J. Mach. Learn. Res, 2019, 21(140): 1-67.
|
| [4] |
Wenzek G, Lachaux M A, Conneau A, et al. CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data[C]// Proceedings of the 12th Language Res-ources and Evaluation Conference, 2020: 4003-4012.
|
| [5] |
Zhu Y, Kiros R, Zemel R, et al. Aligning books and movies: Towards story-like visual explanations by watch-ing movies and reading books[C]// Proceedings of the IEEE international conference on computer vision, 2015: 19-27.
|
| [6] |
Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9.
|
| [7] |
Xiao C, Zhong H, Guo Z, et al. Cail2018: A large-scale legal dataset for judgment prediction[J]. arXiv preprint arXiv:1807.02478, 2018.
|
| [8] |
Chen S, Ju Z, Dong X, et al. MedDialog: a large-scale medical dialogue dataset[C]// Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020: 9241-9250.
|
| [9] |
Xu L, Zhang X, Dong Q. CLUECorpus2020: A large-scale Chinese corpus for pre-training language model[J]. arXiv preprint arXiv:2003.01355, 2020.
|
| [10] |
Grave É, Bojanowski P, Gupta P, et al. Learning Word Vectors for 157 Languages[C/OL]// Proceedings of the Eleventh International Conference on Language Reso-urces and Evaluation (LREC 2018), 2018, https://aclan-thology.org/L18-1550.pdf.
|
| [11] |
Qiu X, Sun T, Xu Y, et al. Pre-trained models for natural language processing: A survey[J]. Science China Techno-logical Sciences, 2020, 63(10): 1872-1897.
|
| [12] |
Sun M, Li J, Guo Z, et al. Thuctc: an efficient chinese text classifier[J/OL]. GitHub Repository, 2016, https://github.com/thunlp/THUCTC.
|
| [13] |
Yuan S, Zhao H, Du Z, et al. Wudaocorpora: A super large-scale chinese corpora for pre-training language models[J]. AI Open, 2021, 2: 65-68.
doi: 10.1016/j.aiopen.2021.06.001
|
| [14] |
Lin J, Men R, Yang A, et al. M6: A chinese multimodal pretrainer[J]. arXiv preprint arXiv:2103.00823, 2021.
|
| [15] |
Zeng W, Ren X, Su T, et al. PanGu-$\alpha $: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation[J]. arXiv preprint arXiv: 2104.12369, 2021.
|
| [16] |
Kudo T. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018: 66-75.
|
| [17] |
Heafield K. KenLM: Faster and smaller language model queries[C]// Proceedings of the sixth workshop on statist-ical machine translation, 2011: 187-197.
|
| [18] |
Lauriola I, Lavelli A, Aiolli F. An introduction to deep learning in natural language processing: models, techni-ques, and tools[J]. Neurocomputing, 2022, 470: 443-456.
doi: 10.1016/j.neucom.2021.05.103
|
| [19] |
Zhang Z, Han X, Zhou H, et al. CPM: A large-scale generative Chinese pre-trained language model[J]. AI Open, 2021, 2: 93-99.
doi: 10.1016/j.aiopen.2021.07.001
|
| [20] |
Lui M, Baldwin T. langidpy: An off-the-shelf language identification tool[C]// Proceedings of the ACL 2012 syst-em demonstrations, 2012: 25-30.
|
| [21] |
Buck C, Heafield K, Van Ooyen B. N-gram counts and language models from the common crawl[C]// Proceed-ings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), 2014: 3579-3584.
|
| [22] |
汤佳杰, 曹永忠, 顾浩. 基于文本标点密度连续和的网页正文抽取[J]. 计算机时代, 2020, 1:69-72.
|
| [23] |
Rivest R, Dusse S. The MD5 message-digest algorithm[J]. RFC, 1992, 1321:1-21.
|
| [24] |
Jaccard P. The distribution of the flora in the alpine zone. 1[J]. New phytologist, 1912, 11(2): 37-50.
doi: 10.1111/j.1469-8137.1912.tb05611.x
|
| [25] |
Gionis A, Indyk P, Motwani R. Similarity search in high dimensions via hashing[C]// Vldb. 1999, 99(6): 518-529.
|
| [26] |
Broder A Z. On the resemblance and containment of documents[C]// Proceedings. Compression and Comp-lexity of SEQUENCES 1997 (Cat. No. 97TB100171), IEEE, 1997: 21-29.
|
| [27] |
Kenton J D M W C, Toutanova L K. BERT: Pre-training of Deep Bidirectional Transformers for Language Under-standing[C]// Proceedings of NAACL-HLT, 2019: 4171-4186.
|
| [28] |
Li X, Meng Y, Sun X, et al. Is Word Segmentation Necessary for Deep Learning of Chinese Representat-ions?[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 3242-3252.
|
 ),ZHONG Zhenyu(
),ZHONG Zhenyu(